Datasets are the foundational component of modern machine learning. They provide the raw data and corresponding labels that allow AI models to learn and make predictions. The following content explores the nature of these datasets, examining the different types of annotations—from simple, coarse-grained labels to complex, fine-grained ones—and highlighting influential datasets that have driven breakthroughs in visual, audio, and textual AI.
Annotations
Datasets consist of raw data and accompanying annotations per sample. In general, the raw data is the independent variable, and the annotations are the dependent variable; the most common objective of an AI/ML model is to learn functions over the independent variable to predict/estimate the dependent variables.
While the annotations are specific to a certain problem, it is worthwhile to review a few examples to get a better insight into it.
Visual Data
Visual data can either be images or videos. Sometimes, visual data are pseudo-color images; it can be volumetric cubes like seismic data in O&G, PET scans in healthcare, etc.
Annotations for video and images do not vary that much. Annotations can be coarse or fine-grained.
Coarse annotations
In general, they are per sample and do not provide image spatial information. A very consistent example for this type of annotation is the ones used for image classification, scene classification, video classification, Action recognition, etc. The dataset format will include the following information:
Image1: class a
Image2: class b
Image3: class a
…
Image classification is the problem where images with a single object (person, animal, etc.) are presented, and the objective is to identify what is present. The dataset for this type of problem contains images and one corresponding label for each image. Sometimes multiple labels are used in multi-class classification problems. Examples:
Video Classification is similar in the sense that the input is a video, and the objective is to predict the label for the video. The label can just be the video genre, or it could be action performed by a human in action recognition. Examples:
Fine-grained annotations
In the context of images, datasets may include image spatial annotations. For example, bounding box annotations, where objects in an image are labeled with a box. The dataset can include the following information:
Image1: class a, x, y, height, width
Image2: class b, x, y, height, width
Image3: class a, x, y, height, width
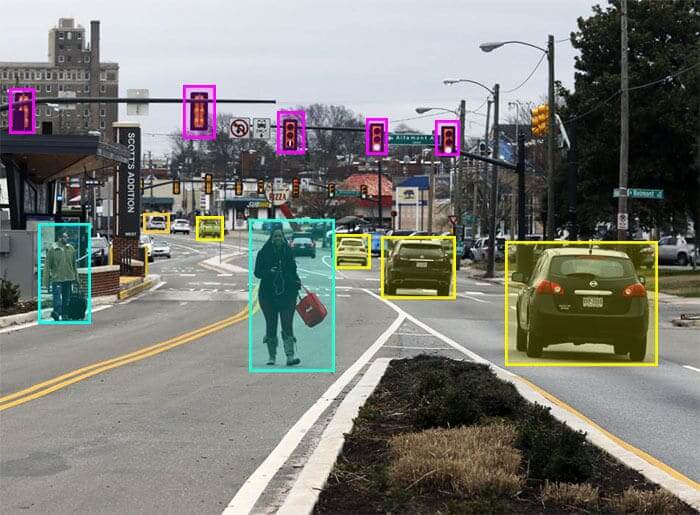
Figure: Image with multiple bounding box annotations per image
Another example is mask annotations, where each image is accompanied by a binary mask. The mask indicates what pixels in the image correspond to an object. The dataset can include the following information:
Image1: class a, binary mask
Image2: class b, binary mask
Image3: class a, binary mask

Figure: Image with multiple mask annotations per image (source: [Link](https://www.superannotate.com/blog/guide-to-semantic-segmentation))
Object detection is a popular example of a problem that requires bounding box annotations. Given an image, all the objects of interest are labeled with a bounding box. The task of object detection is to take an image as input and to identify and localize objects in the image. Examples:
Segmentation is an example where mask annotations are needed. Some segmentation problems are well defined; examples include background segmentation, object segmentation, scene segmentation, etc. Example
- COCO (also provides masks for objects): Link
Fine-grained annotations, in the context of videos, can simply include bounding box annotations or mask annotations for each image in the video.
Other types of annotation may include annotations for temporal video segmentation, where a video is divided into distinct scenes. Or labels for anomaly detection that can be both fine-grained or coarse-grained, etc. Other examples of video datasets:
- UCF-crime: Link
Accurate fine-grained annotations are of great value for many problems, but are also extremely time-consuming and tedious to generate.
Audio Data
Audio data, like visual data, can be annotated to train machine learning models. The annotations range from coarse, whole-audio labels to fine-grained, time-specific annotations. The choice of annotation type depends on the specific problem being addressed, such as music genre classification, speech recognition, or sound event detection.
Coarse Annotations
Coarse annotations for audio data typically apply to the entire audio clip and don’t provide temporal information. This is similar to how image classification provides a single label for a whole image.
Audio classification is a broad category where the goal is to assign a single label to an entire audio clip. This can include: Music Genre Classification, where the objective is to identify the genre of a song (e.g., rock, classical, jazz). The dataset for this problem consists of audio files and one corresponding genre label per file. Examples:
Speech/Speaker Identification determines who is speaking or if the audio contains speech. The label could be the speaker’s identity or simply “speech” or “non-speech.” Examples:
Fine-Grained Annotations
Fine-grained annotations for audio data include temporal information, pinpointing where specific sounds or events occur within an audio file. This is crucial for tasks that require precise localization. This type of annotation provides timestamps for specific events or segments within an audio file. An audio file of a busy street might have annotations like:
0.5s - 2.0s: 'car horn'
3.2s - 4.5s: 'siren'
6.0s - 7.5s: 'dog bark'
Sound Event Detection (SED) is a good example of a problem that requires fine-grained annotations. The goal is to identify and localize sounds in an audio clip by providing start and end times for each sound event. This is similar to object detection in images. Examples:
Like fine-grained visual annotations, creating high-quality fine-grained audio annotations is extremely time-consuming and labor-intensive. It requires human annotators to listen carefully and mark the precise start and end points of events, making it a valuable but costly part of dataset creation.
Textual Data
Just like images, video, and audio, textual data requires annotation to become useful for training AI models, especially in the field of Natural Language Processing (NLP). The process, often called text annotation or data labeling, involves tagging or labeling text to give it structure and meaning that a machine can understand.
Coarse Annotations
Similar to image or audio classification, coarse annotations for text involve assigning a single label to an entire document, paragraph, or sentence. This type of annotation is used for problems where the overall meaning or characteristic of the text is the primary focus. Many problems fall under the broad area of text classification. Sentiment Analysis: This is a very common example. An entire block of text, like a product review or a social media post, is labeled as “positive,” “negative,” “neutral,” or even with a more specific emotion like “joy,” “anger,” or “sadness.” Example: Social Media Sentiment: Link Amazon Reviews: Link
Fine-Grained Annotations
Fine-grained annotations for text are more detailed, providing information about specific words, phrases, or relationships within the text. This is analogous to bounding boxes or masks in visual data. Named Entity Recognition (NER): This is one of the most fundamental fine-grained text annotation tasks. It involves identifying and labeling proper nouns or other specific entities. Example annotation: In the sentence “Steve Jobs co-founded Apple in Cupertino,” the annotations would be:
"Steve Jobs": PERSON
"Apple": ORGANIZATION
"Cupertino": LOCATION
Example:
- NER: Link
Influential Datasets
Not all datasets are the same; some have such a deep influence on today’s advancements that the majority of the AI/ML models that one may find in multimedia research are usually pretrained on these datasets. Let’s consider the following:
Visual understanding problems
Imagenet is a large-scale dataset with 14 million images spanning across 20k categories. The dataset initially contained coarse labels, one category name for each image, and was later expanded to have fine-grained bounding box annotations. It was accomplished by crowd-sourcing the annotation work using Amazon Mechanical Turk, and it took nearly 2 years and around 50K participants to have the first version of the dataset.
The majority of the visual recognition tasks today, be it for video or images, use neural nets trained on Imagenet as a backbone to extract features to use them in downstream tasks.
COCO from Microsoft is also a cornerstone dataset for object detection, segmentation, and image captioning. It contains over 330,000 images with detailed annotations for 80 object categories. Also annotated using crowdsourcing.
Audio understanding problems
AudioSet is a massive dataset of over 5 million YouTube videos, each annotated with labels from an ontology of 527 sound events. It’s the most common dataset used for pre-training models for tasks like sound event detection and audio classification.
LibriSpeech is the definitive dataset for speech recognition. It’s a corpus of nearly 1,000 hours of English speech from audiobooks, all with corresponding text transcripts. Models like Wav2Vec and its successors, which have revolutionized speech recognition, are frequently pre-trained on this and similar large, unlabeled speech corpora to learn general speech features before being fine-tuned for specific tasks.
While these are large-scale datasets, they are not annotated via crowdsourcing. AudioSet is manually labeled by human annotators, and LibriSpeech is derived from existing audiobooks.
Textual analysis problems
BooksCorpus (800 million words) and the English Wikipedia (2.5 billion words) are two large-scale datasets. BERT (Bidirectional Encoder Representations from Transformers) by Google was a breakthrough in NLP. Fine-tuning a pre-trained BERT model has become a standard approach for a wide range of tasks, from question answering to sentiment analysis.
The Common Crawl dataset contains petabytes of web data and a variety of books, articles, and other internet texts. OpenAI’s GPT series is trained on these datasets and is often used as a starting point for developing new language models.
Textual datasets like these are annotations in themselves, or do not need annotations for tasks like training LLMs.
Emerging directions of research
A few directions of research that may be of interest to us. Multimodal AI AI models that are trained on multiple modalities (text, audio, video) are becoming increasingly relevant. Research in these areas focuses.
- Methods to extract common features from two or more modalities with the same semantic meaning.
- Methods to fuse features from various modalities.
- Cross-attention models that dynamically understand the importance of features across modalities. etc.
Example datasets and applications
COCO’s VQA dataset is a text and image modal dataset for AI. These datasets allow for solving Vision-and-Language (V&L) tasks like Visual Question Answering (VQA), multimedia data retrieval, image captioning, etc.
YouTube-8M and MuSe (Multimodal Sentiment Analysis), which combines video and audio to analyze emotions Human-Centric AI Datasets are becoming more focused on capturing complex human behavior, interactions, and safety-critical scenarios. This is particularly relevant for applications in social robotics, healthcare, and safety systems.
Example datasets and applications Egocentric Video Datasets (e.g., Ego4D) are collected from a first-person perspective (e.g., using a camera on a headset). They are crucial for understanding human-object interaction and for training models that can assist with daily tasks
Some insights.
- The most influential datasets are generally large, containing hundreds of thousands to millions of samples, and often rely on human annotators for fine-grained labels in image and audio modalities. Historically, these influential datasets have been made publicly available, fostering widespread research and innovation.
- However, it’s crucial to note that domain-specific, application-specific proprietary datasets can hold significant commercial value. The entities interested in these datasets are typically found in the private, commercial, retail, and public sectors, as they are tailored for specific business problems rather than general academic research.